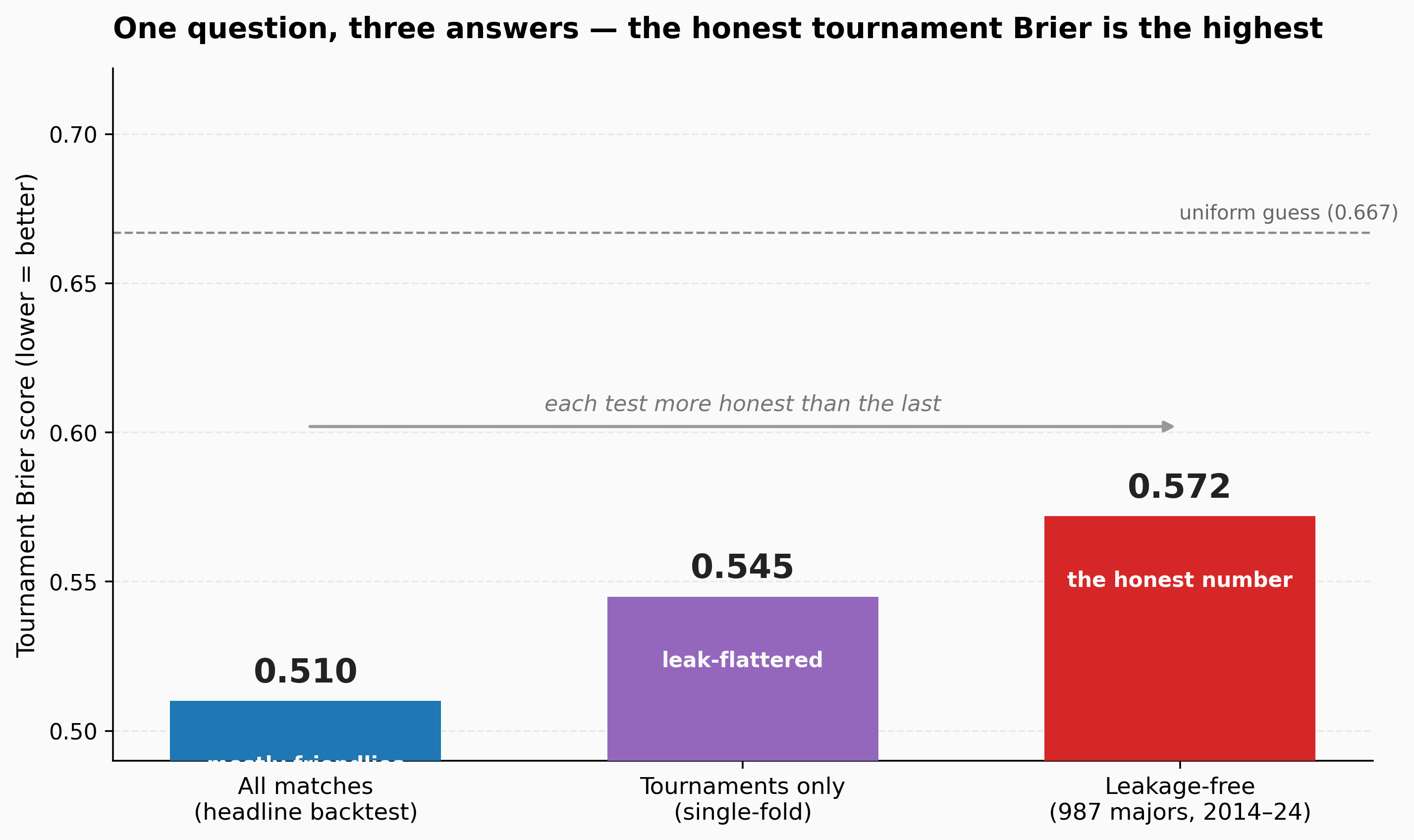
We have published three different Brier scores for the same question — how accurate is this model on tournament matches? — and each one is worse than the last. That isn't drift or error. Each number comes from a more honest test than the one before it, and the honest answer is the highest of the three: 0.572.
This post is the reconciliation, because if you read around the site you will find all three numbers, and you deserve to know which one to trust. (Lower is better for Brier; a uniform 1/3, 1/3, 1/3 guess scores 0.667.)
Number one: 0.510 — the headline backtest
The methodology page reports an ensemble Brier around 0.510 on a five-year holdout: train on everything before 2021-05-23, score everything after. That window holds 5,102 international matches in the common subset where every component model produced a prediction.
The catch is in the mix. Only 881 of those matches (16.5%) are major-tournament games — World Cup, Euro, Copa América, AFCON, Asian Cup, Gold Cup. The other 83.5% are friendlies, qualifiers, and Nations League. A reader who sees "Brier 0.510" and assumes the model is that sharp on a June 2026 World Cup match is reading a number dominated by friendlies.
Number two: 0.545 — tournaments only
So we re-ran the identical backtest with the evaluation slice filtered to tournament matches only. Same training data; only the matches being scored change.
| Model | Brier (all matches, n=5,102) | Brier (tournaments only, n=797) | ΔBrier |
|---|---|---|---|
| Elo | 0.5159 | 0.5448 | +0.0289 |
| Dixon-Coles | 0.5106 | 0.5461 | +0.0355 |
| Hierarchical Poisson | 0.5154 | 0.5499 | +0.0345 |
| Ensemble (uniform avg) | 0.5102 | 0.5450 | +0.0348 |
Every model is meaningfully worse on tournaments — about 7% higher Brier, a consistent gap well outside the noise band at n=797. For a while we treated 0.545 as the honest number, and said so.
One thing worth keeping from this slice: the component ranking shifts. On all matches, Elo is the worst single model and the ensemble beats every component. On tournaments, Elo (0.5448) nominally edges Dixon-Coles (0.5461) and ties the ensemble (0.5450) on Brier — within noise, but the "ensemble beats everything" story stops being clean. On log-loss the ensemble still wins decisively (0.9204 vs Elo's 1.1205), because log-loss punishes Elo's overconfidence far harder than Brier does. The read: on the matches that matter, the rating you walk in with carries most of the information.
Number three: 0.572 — with the leak removed
Then we found the problem with 0.545.
That backtest, like the production walk-forward, composes its ensemble using the current team-rating (Elo) snapshot rather than each team's rating as it actually stood on the match date. For matches deep in the past that barely matters. For recent matches — which dominate a 2021–2026 evaluation window — today's snapshot is nearly identical to the teams' true contemporaneous ratings, so a sliver of future information leaks backward into the score. The effect is small, but it pushes the Brier down: the model looks slightly sharper than a forecaster standing before those matches could have been.
To kill the leak entirely, we rebuilt the calibration retrospective from scratch. For each of the 24 major-tournament editions from 2014 to 2024, the model is reconstructed exactly as it stood the day before that tournament's first match:
- Dixon-Coles and Hierarchical Poisson refit on matches strictly beforehand;
- Elo rolled forward match-by-match to each team's pre-match rating, never the modern snapshot;
- the tournament-tier calibration layer refit on only the 24 months before the cutoff.
No data from the tournament, or any later match, touches any layer. Across all 987 matches, the leakage-free ensemble scores:
| Metric | Leakage-free retro (987 matches, 2014–2024) |
|---|---|
| Brier | 0.572 |
| Expected calibration error | 5.6pp |
| Log-loss | 1.00 |
| Uniform-guess baseline (Brier) | 0.667 |
The three World Cups in that set score 0.565 (2014), 0.569 (2018), and 0.611 (2022) — the 48-team 2026 edition is the next data point. You can browse the full per-tournament breakdown, with reliability diagrams, on the calibration scoreboard.
So the genuinely honest tournament number is 0.572, not 0.545 and certainly not 0.510. It is the only one of the three with no look-ahead in any component.
Why tournaments are hard, and what 0.572 means
A 0.572 Brier on tournament football is not a weak model — it is close to the entropy floor for outcomes this variable. Knockout matches reset; group-stage line-ups rotate; managers experiment in ways they never would in a qualifier. The uniform baseline is 0.667, and a strong published random-forest baseline on rating features sits near 0.46 on much easier all-match samples. Tournament prediction lives in between, and high-variance reality keeps it there.
For WC 2026, hold us to 0.572. When the post-tournament calibration retrospective lands, the 64 matches of this World Cup should be scored against that number — not the friendlier 0.510, and not the leak-flattered 0.545. If we land near 0.572 with a flat reliability diagram, the model did exactly what its backtest promised. If we land well below it, we got lucky; well above, and there is something to explain.
Where to read more
The leakage-free retro scoreboard — every tournament, every reliability diagram — is at /docs/calibration/. The single-fold tournament-slice note (numbers two above) is at /research/notes/tournament-only-backtest/, and the full methodology at /docs/methodology/.
Numbers in this post come from two backtests: the single-fold tournament slice (scripts/backtest_models.py --folds 1 --backtest-days 1825 --tournaments-only --today 2026-05-22) and the leakage-free retro scoreboard (scripts/build_retro_tournament_calibration.py). They are for research and educational purposes only — not betting advice, not financial advice, not recommendations to gamble. The model can be wrong. Methodology: /docs/methodology/. Full Terms of Use.