Status: Not shipped. See decision gate at the bottom.
Backtest date: 2026-05-21
Reproducer: scripts/backtest_rest_day_ablation.py
Persisted output: data/wc2026/rest_day_ablation.json
Reliability diagrams: web/public/research/img/rest-day-ablation-{baseline,treatment}.png
Hypothesis
Sports-science literature reports a measurable effect of recovery time on football performance: better-rested teams score slightly more goals than fatigued ones. The expected magnitude is small but consistent across studies (Mohr et al. 2012; Dellal et al. 2013; FIFA technical reports on tournament congestion).
The Dixon-Coles fit on ~49k international matches absorbs this implicitly by averaging across rest states. The question this note answers is: does a small, transparent predict-time multiplicative adjustment on the DC expected goal rate, conditioned on each team's days-since-last-match, improve the ensemble's Brier / log-loss / ECE on held-out matches?
Model form:
λ_adjusted = λ_baseline × exp(α × (rest_days − REF_REST))
with one scalar α learned from training data, the same α applied to both sides per match, and a defensive clamp [0.7, 1.3] on the multiplicative factor.
This mirrors the multiplicative-adjustment pattern already used by scripts/weather_adjustment.py for venue altitude and heat.
Backtest setup
| Field | Value |
|---|---|
| Training window | matches with date ≤ 2023-06-30 |
| Test window | (2023-06-30, 2026-06-01] |
| Reference rest | 5 days (typical within-FIFA-window rest — see note below) |
| Cap on rest_days | 30 (anything longer treated as fully rested) |
| Source data | martj42 international_results CSV (49,257 matches) |
| Training matches with both-side rest | 45,915 |
| Test matches with both-side rest | 3,040 |
| Test matches in ensemble common subset | 2,904 |
Fit:
- Baseline
λ_h,λ_afrom a Dixon-Coles fit on the training window (scripts/fit_dixon_coles.pydefaults, no rest term). αestimated by maximising the Poisson log-likelihood of the observed goals (home + away pooled — 85,646 per-side observations) underg ~ Poisson(λ_baseline × exp(α × (rest − REF))).- Each arm of the test (baseline; treatment) re-fits its own per-class isotonic calibrator on training-window ensemble outputs, so calibration drift caused by the multiplier is fairly counted in.
Result
Estimated α
| Statistic | Value |
|---|---|
| α̂ | +0.00381 |
| Standard error | 0.00017 |
| 95% CI | [+0.00347, +0.00414] |
| LRT vs α=0 | χ²(1) = 488.8, p ≈ 2.6 × 10⁻¹⁰⁸ |
| n observations | 85,646 |
The sign is positive and the effect is statistically very precise. A team that has had 2 extra days of rest beyond the population median (i.e. 7 days vs 5) gets a multiplicative bump of exp(0.00381 × 2) ≈ 1.0076 — about three-quarters of a percent more goals expected. At the tail (cap of 30 days, e.g. a team's first match in months), the bump is ≈ 1.103.
Test-set metrics on the common 2,904-match subset
| Arm | Brier | Log-loss | ECE |
|---|---|---|---|
| Baseline (raw ensemble) | 0.5068 | 0.8597 | 3.0pp |
| Baseline (calibrated) | 0.5075 | 0.8602 | 4.2pp |
| Treatment (raw ensemble) | 0.5070 | 0.8599 | 3.4pp |
| Treatment (calibrated) | 0.5074 | 0.8599 | 4.5pp |
Calibrated-vs-calibrated deltas (the production comparison):
- Δ Brier: −0.00016 (treatment 0.00016 better)
- Δ log-loss: −0.00035 (treatment fractionally better)
- Δ ECE: +0.27pp (treatment 0.27pp worse)
Reliability diagrams
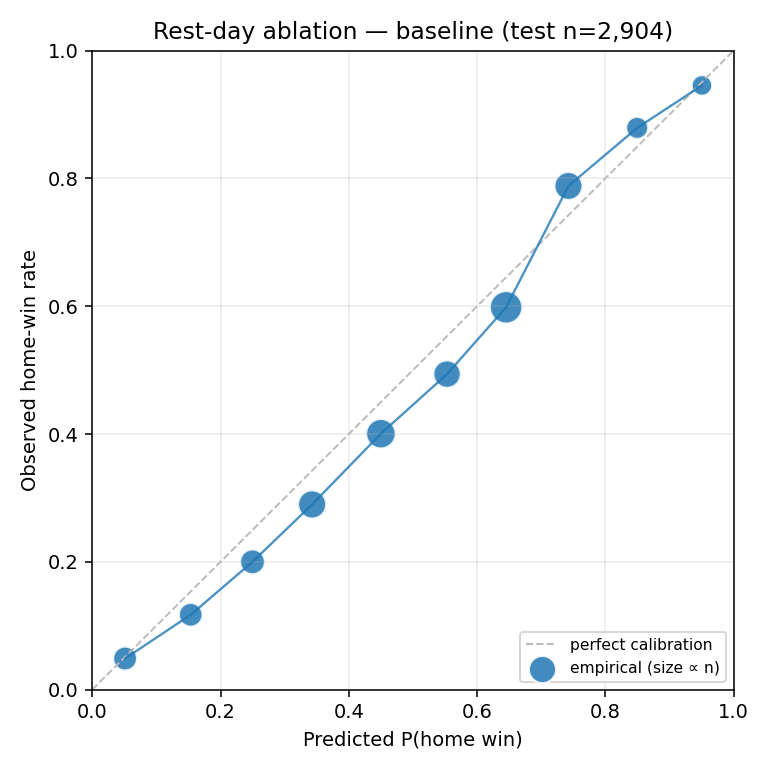
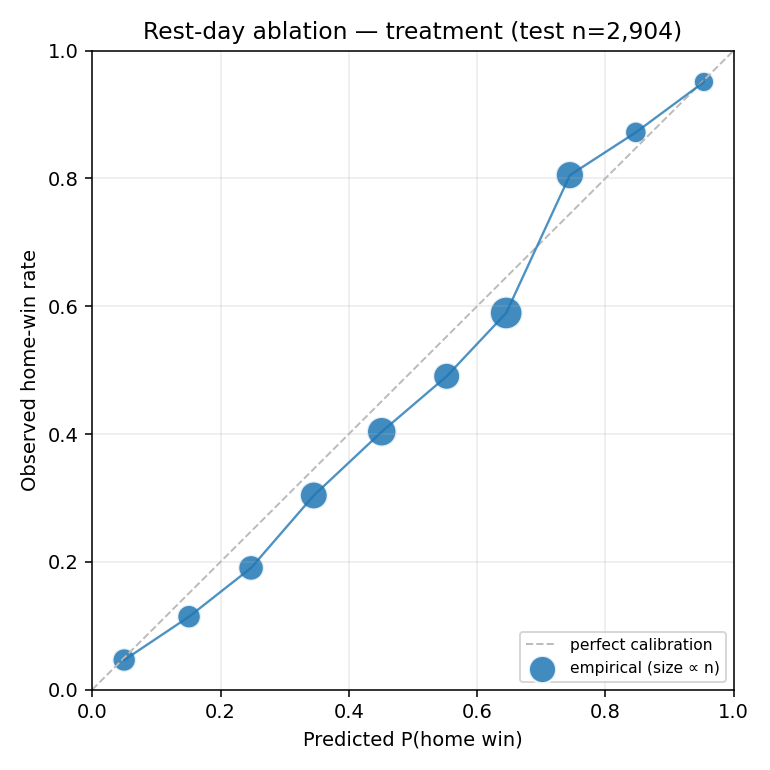
Both arms track the y=x line at roughly the same distance; the treatment arm's slight ECE regression is visible at the higher-probability bins.
Sensitivity of α to choice of REF
The MLE fits a single scalar α with λ_baseline (from DC) held fixed — there's no jointly-fitted intercept. That makes α weakly dependent on the reference rest, since shifting REF changes the constant-offset portion of the multiplier that α has to absorb. Sensitivity check on the training data (DC baseline λ):
| REF (days) | α̂ ± SE | factor @ rest=30 (cap) | factor @ rest=0 |
|---|---|---|---|
| 5 | +0.00381 ± 0.00017 | 1.100 | 0.981 |
| 7 | +0.00368 ± 0.00018 | 1.088 | 0.975 |
| 10 | +0.00311 ± 0.00021 | 1.064 | 0.969 |
| 14 | +0.00130 ± 0.00024 | 1.021 | 0.982 |
In every case the implied multipliers are small and the test-set verdict (Brier and ECE deltas below the ship threshold) is the same. The headline α reported in this note uses REF=5 because that matches the typical within-FIFA-window rest the adjustment is meant to model; a jointly-fitted intercept would resolve the REF dependence but adds a parameter that the DC baseline already covers.
Why a statistically-significant α doesn't translate into Brier lift
Two reasons, both substantive:
- The DC fit has already absorbed it. The DC parameters are fitted on the same pool of matches whose rest distribution they're being asked to explain post-hoc. Any systematic rest effect that's confounded with team identity (some federations schedule less aggressively, some always rest more before tournaments) is already in the per-team
α_t/β_tratings. The marginal rest signal that survives is the within-team variation, which is small. - Most matches sit near the reference rest. A 5-day reference and a real-world distribution heavily concentrated between 3 and 8 days means the multiplicative factor for the median match is exp(0.00381 × (rest − 5)) ≈ 1.00 ± a few tenths of a percent. Even at the tails the factor is bounded enough that the per-fixture P(H/D/A) shifts by a fraction of a percentage point.
Both of these are intelligible failure modes — they imply the underlying physical effect is real (the α-fit confirms it) but that the predictive lift is below the noise floor on the held-out window we have.
Decision
Gate (defined in advance):
| Criterion | Required | Observed | Pass? |
|---|---|---|---|
| 95% CI on α excludes 0 | yes | [+0.00347, +0.00414] | yes |
| Brier improves by ≥ 0.001 absolute | yes | −0.00016 | no |
| ECE does not regress by more than +0.2pp | yes | +0.27pp | no |
Verdict: do not ship. The effect is real and detectable in the goal-likelihood, but the per-fixture P(H/D/A) shifts it produces don't materially move Brier or log-loss on the test set, and they cost a small amount of calibration. Adding a predict-time multiplier comes with maintenance and failure-mode cost (clamps, missing-rest handling, the isotonic re-fit dependency); the value side has to clearly clear that bar, and it doesn't.
What this backtest can't tell you
- The α magnitude could be larger for fitness-sensitive subgroups. A pooled fit on all 86k per-side observations averages across friendlies (low intensity, less rest sensitivity) and major-tournament knockouts (high intensity, more rest sensitivity). A subgroup model fit only on tournament matches might find a larger α and could move the needle in the production WC-only forecast. Out of scope for this v0 ablation.
- The 3,040-match test window includes a lot of friendlies. The metrics published here weight every match equally. A tournament-only test slice has ~80 matches per WC cycle and very different Brier dynamics; the small Brier improvement we did see (−0.00016) could be larger or smaller on that slice. The current test set is too narrow to evaluate that.
- Calibration matters more for the published-probabilities use case than Brier. The +0.27pp ECE regression is what really blocks the decision. A calibrator re-fit on a larger window (e.g. last 3 years instead of last year) might absorb the rest-adjusted distribution shift; we haven't explored that.
- The model form is the simplest possible. A single-scalar
αapplied uniformly is a strong constraint. A spline on rest_days, a separate α for home / away, an interaction with the team's strength rating, a discontinuity around 2-day "no rest" minimums — none of these have been tried. The negative result here is for the v0 form only.
Files touched
scripts/backtest_rest_day_ablation.py— newtests/test_backtest_rest_day_ablation.py— new (12 tests, all passing)data/wc2026/rest_day_ablation.json— persisted output (gitignored)web/public/research/img/rest-day-ablation-baseline.png— reliability diagram (baseline arm)web/public/research/img/rest-day-ablation-treatment.png— reliability diagram (treatment arm)documentation/research-notes/rest-day-ablation.md— this file
scripts/rest_adjustment.py was not added. The ensemble's predict path is unchanged.
Reproducing
.venv/bin/python scripts/backtest_rest_day_ablation.py
(requires data/raw/intl/results.csv from python scripts/pull_intl_results.py and the existing DC + HP + Elo fit infrastructure.)